Exploring News Through Data
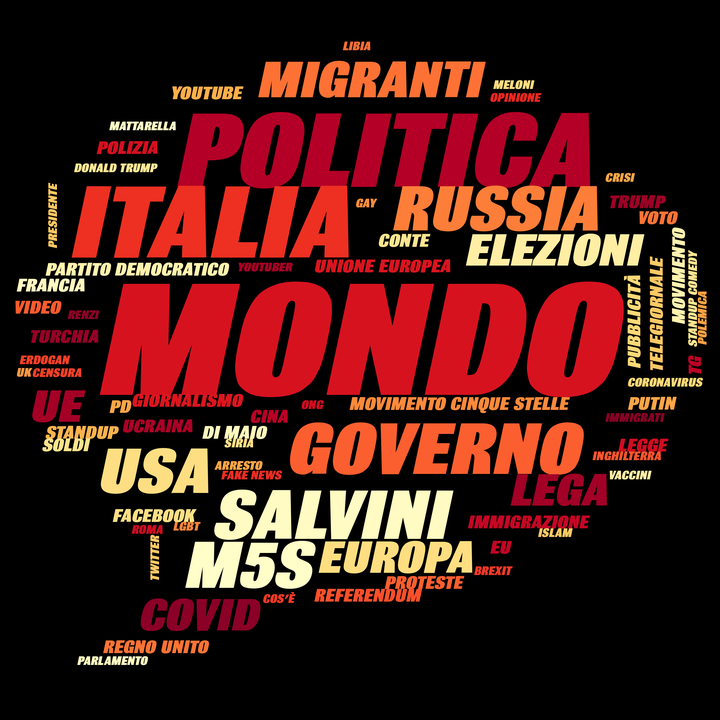 Breaking Italy keyword cloud
Breaking Italy keyword cloudBreaking Italy has been my favorite infotainment YouTube channel since I was in high school. It’s one of the largest YouTube communities in the Italian scene, and it features a mix of news and opinions. What I love the most about the channel is that Alessandro Masala, the creator and host of the show, always makes an effort to provide the backstory for the news, and this allows you to have an eagle-eye on what is happening in the world. Alessandro also provides a wealth of references that any user can use to read more about each topic discussed in the video.
I have often found myself looking for a reference, be it a newspaper article or a report, that I wanted to read again but I was unable to because I had no way to quickly search through the thousands of videos Breaking Italy has posted over the years. This presented me with a great opportunity to try the YouTube Data API and use my coding skills. At the time, I was mostly interested in finding a Gender Gap report that Alessandro talked about in one of his videos.
What’s in the Mix
I rolled up my sleeves and jumped into the data behind the scenes. With 1068 videos in the mix, I took the YouTube Data API for a spin, snagging titles, keywords, and descriptions. Here’s three tasks I worked on:
WORD CLOUD SYNTHESIS: For each of the 1068 videos, I have extracted keywords from the description, the title and the YouTube keywords. I have used this information to craft a word cloud that captures the essence of those videos in a single visual. Give it a go.
REFERENCES SEARCH ENGINE: Each video provides a wealth of references used to inform the journalist. These are often gathered by topic and may or may not have a description. The way these references have been provided has changed multiple times throughout the years, in other words this required messy RegEx and text processing. Try the code.
- Extracted URLs from video descriptions.
- Inferred their content based on description text, video title and keywords.
- Generated a dictionary with keywords as keys and lists of URLs matching those keywords as values.
- Wrote Javascript software for a Search Bar that finds all the URLs matching the intersection of the keywords provided by the user.
SENTIMENT ANALYSIS AND LDA: Breaking Italy’s videos usually feature 3 major news and some smaller ones. I decided to start with a monothematic episode “What happened in Russia with the Wagner company?”.
- Processed comments’ emojis using the emojy package.
- Removed Italian stopwords using the NLTK.
- Latent Dirichlet Allocation with GenSim.
- For each topic, run Sentiment Analysis in Italian with Polyglot.
- Visualization with pyLDAvis.
Of course, there are many limitations to this. First and foremost, working with social media data, such as comments, can be messy due to high levels of sarcasm, inner-jokes, and general internet references (memes, emojis, set phrases). Another limitation is that these videos don’t have very large numbers of comments, limiting the generalization of the results. Nonetheless, I found the results very interesting. It is generally quite difficult to give a rule-of-thumb for the number of topics for LDA, but upon reading the comments myself, I thought there would be less than $5$ major topics. Using $n=3$ we obtain the following output (translated by me):
LDA Topics:
(0, '0.019*"joy" + 0.019*"tears" + 0.007*"video" + 0.006*"state" + 0.005*"before" + 0.005*"mercenaries" + 0.005*"never" + 0.004*"do" + 0.004*"toilet" + 0.004*"Moscow"')
(1, '0.007*"history" + 0.006*"only" + 0.005*"Russia" + 0.005*"war" + 0.005*"state" + 0.005*"mercenaries" + 0.004*"me" + 0.003*"Moscow" + 0.003*"part" + 0.003*"video"')
(2, '0.006*"thanks" + 0.006*"work" + 0.005*"always" + 0.005*"smile" + 0.005*"uproariously" + 0.005*"war" + 0.005*"state" + 0.005*"only" + 0.004*"excellent" + 0.003*"later"')
Topic: 0 - Polarity: -0.12
Topic: 1 - Polarity: -0.0379746835443038
Topic: 2 - Polarity: 0.1891891891891892
Topic 2 gathers comments thanking the creator for making the video and, this is reflected in the polarity. Topic 3 contains mostly comments either explaining what happened, correcting the creator, starting a discussion on the topic, or generally just talking plainly about what happened. Upon reading some of the comments in this topic myself, I am unsure why the polarity is not lower. Finally, the first topic, is the trickier one and requires context to be understood. In the video the creator makes a joke about getting a notification about this news while on the toilet (he makes other jokes towards his community later on in the video). This topic mostly gathers jokes, laughs, statements of surprise or ridiculising what happened, references to this one joke “toilet”. Importantly, the first two words come from repeated use of the face-with-tears-of-joy emoji. It seems clear that the polarity did not capture sarcasm. The topics are not fully separated since a good portion of users wrote comments containing both jokes and serious statements. Of course, a much more elaborate preprocessing of comments would allow better insight. Although this is just a simple and preliminary analysis, I did find the results interesting. Try the Code.
Why it Resonates with Me
I’m a data journalism enthusiast to the core, and Breaking Italy is one of my go-to for insights. However, I’d watch videos and months later, I’d struggle to find those references buried in the descriptions. So, I put my data science hat on and thought, “Why not blend my passions?”. This was a genuine itch I needed to scratch. Hopefully, I have create something practical — something that helps not just me, but anyone who’s ever found themselves lost in the vast sea of videos of Breaking Italy.
Mauro Camara Escudero
Machine Learning Engineer
My research interests include approximate manifold sampling and generative models.